


How mature is the technology for automatically generating IFC data from point cloud data?
The construction and architecture industries are at the forefront of a digital transformation, largely driven by Building Information Modelling (BIM) and the integration of Industry Foundation Classes (IFC). A critical aspect of this transformation is the automation of generating IFC data from point cloud data—a process with the potential to vastly improve building documentation, renovation, and facility management. However, the maturity of this technology, the current state of automation, and its limitations require closer examination.
This blog post explores these aspects, supported by data, research, and case studies from the UK.
Understanding point cloud data and IFC
Point cloud data consists of millions to billions of data points that represent the 3D coordinates of a building or structure’s surfaces, typically captured by laser scanners or LiDAR systems. These point clouds provide an incredibly detailed digital representation of the physical environment, serving as the raw input for generating BIM models.
IFC is a standard data format used in BIM to describe, share, and exchange building and construction data across different software platforms. IFC files encapsulate detailed information about building elements, including their geometry, properties, and relationships, ensuring seamless interoperability in project workflows.
Current state of automation in generating IFC from point clouds
Automation of IFC generation from point clouds involves several stages, each with varying levels of technological maturity:
1. Object recognition and feature extraction
The first step in the automation process involves recognising and extracting architectural features such as walls, windows, and doors, from point cloud data. Advances in machine learning, particularly deep learning algorithms, have significantly enhanced this process. Research shows that in relatively simple environments, feature extraction algorithms can achieve accuracy rates of 85-90%. However, this accuracy declines sharply in more complex, cluttered, or occluded settings. A systematic review by Drobnyi et al. (2023) explores the construction and maintenance of geometric digital twins, identifying key challenges and knowledge gaps that must be addressed to facilitate the efficient automation of geometric digital twin generation and maintenance from PCD. One key issue is the difficulty in comparing classical computer vision methods due to their evaluation on different private datasets. This makes it hard to determine which methods work best for different object types. Evaluating these methods on public datasets would facilitate fairer comparisons. Additionally, existing non-machine learning methods lack generalisability for arbitrary buildings and objects, as they often rely on specific assumptions, making them less practical in real-world scenarios with noise, clutter, and occlusions. Deep learning could play a crucial role in developing more generic and robust methods for object detection and matching.
Moreover, traditional computer vision methods struggle with detecting complex, non-primitive shapes, such as pipe joints or light fixtures, across diverse environments. Deep learning offers a potential solution, but designing methods that can robustly detect these complex shapes remains a challenge. Matching object instances between PCD and reference models is also difficult, especially when their locations deviate significantly. Current methods are more suited for progress monitoring than quality control, indicating a need for improved approaches, such as unsupervised clustering or object composition analysis. The study also discusses the limitations of deep learning methods due to the scarcity of labelled 3D data in the built environment. Using synthetic data for training might help address this, but questions remain about the amount of real-world data needed and how best to integrate synthetic data. Finally, PCD acquisition techniques struggle to capture transparent and specular objects, integral to buildings, as these objects often get mislocated or removed as noise. Incorporating 2D image analysis could help, but seamlessly combining 3D and 2D data remains a challenge.
Addressing these challenges, a recent study from the University of Cambridge investigated the accuracy of object recognition in heritage buildings, where intricate details and non-standard geometries present substantial hurdles. The study found that while algorithms could reliably detect basic structures like walls and floors, they struggled with more detailed elements such as cornices and ornate windows, often misclassifying or missing them entirely. The Construction Information Technology (CIT) Laboratory at Cambridge has also made strides in this area with an AI-based 3D reconstruction handheld visual laser system designed for precise and rapid capture of complex 3D structures. This device “PointPix” reduces the cost and time involved in digitising infrastructure assets by devising a mobile scanning system able to digitise the geometry of man-made structures with high accuracy and density while scanning over long distances. The device utilises a combination of deep learning-based image-guided depth completion and visual-lidar odometry/SLAM to fuse high-resolution images from a camera and relatively lower-resolution 3D laser measurements from a LiDAR sensor.
2. Semantic labelling and IFC classification
Once objects are recognised, the next phase involves classifying them into appropriate IFC entities, such as IfcWall or IfcWindow. This process, known as semantic labelling, is essential for creating a functional BIM. Current automation techniques for semantic labelling achieve accuracy rates between 70-85%, depending on the structure’s complexity. Under the BUILDSPACE project, the University of Cambridge offers digital twin construction services, where they successfully converted a .txt file into an .ifc format digital twin, preserving accurate spatial relationships. This conversion is a critical step in constructing digital twins for intelligent management of existing assets. Learn more about the project here and here.
3. Integration with BIM workflows
Integrating automated IFC generation into existing BIM workflows is essential for practical application. While tools like Autodesk ReCap, Bentley’s ContextCapture, and Trimble RealWorks offer partial automation, they often require 30-50% manual editing to refine the generated models, particularly in large-scale infrastructure projects. For instance, the Crossrail project in London, one of the UK’s largest infrastructure projects, has been a significant case study in the application of automated IFC generation. The project’s digital twin approach, which involved creating highly detailed IFC models of the entire rail network, revealed the limitations of current automation technologies. Despite using cutting-edge tools, the need for extensive manual correction and refinement was a recurring issue, highlighting the gap between current capabilities and the ideal of fully automated BIM processes. Addressing these challenges, the digital twin product construction and maintenance group at the University of Cambridge’s, focuses on the research needed to improve the workflow from point cloud data to digital twins for both buildings and infrastructure. For more details, visit their website.
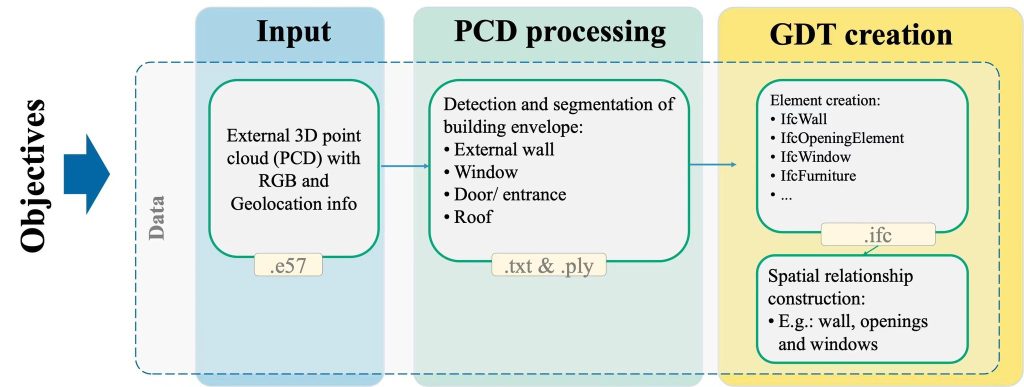
Figure 1: Scan-to-digital twin workflow
Limitations from current automation technologies
Despite promising advancements, several limitations prevent the full automation of generating IFC data from point clouds:
• Accuracy and precision: As noted earlier, object recognition and semantic labelling algorithms, while improving, still face accuracy challenges, especially in complex or cluttered environments. This leads to error rates of 10-30% depending on the environment, necessitating manual corrections.
• Computational complexity: Processing large-scale point cloud datasets, often exceeding 10 billion points for large infrastructure projects, is computationally intensive. Even with high-performance computing, processing times can range from several hours to days, limiting the practicality of fully automated workflows.
• Interoperability and standardisation: Although IFC provides a standardised format, the lack of standardisation in the methods and tools used for generating IFC from point clouds can lead to inconsistencies in the data. This affects the reliability and interoperability of the models across different BIM platforms.
• Semantic understanding: Current technologies struggle with capturing and accurately interpreting the semantic relationships between different building components. This limitation is particularly evident in projects involving historic or non-standard structures, where traditional design norms do not apply.
The future of IFC automation: What next?
The future of automating IFC generation from point clouds is bright, with ongoing research aimed at overcoming current challenges. Key areas of focus include:
• Enhanced machine learning models: Future advancements in machine learning, particularly in deep learning and reinforcement learning, are expected to improve object recognition and semantic labelling accuracy. For instance, models that can learn from smaller datasets and adapt to different environments will be crucial.
• Real-time processing: As cloud computing and edge computing technologies advance, real-time processing of point cloud data is becoming more feasible. This will enable faster generation of IFC models, reducing the reliance on manual intervention.
• Standardised workflows: Developing standardised workflows and best practices will be essential to ensure consistency and reliability in the generated IFC data. This will likely involve collaboration between software developers, industry professionals, and regulatory bodies.
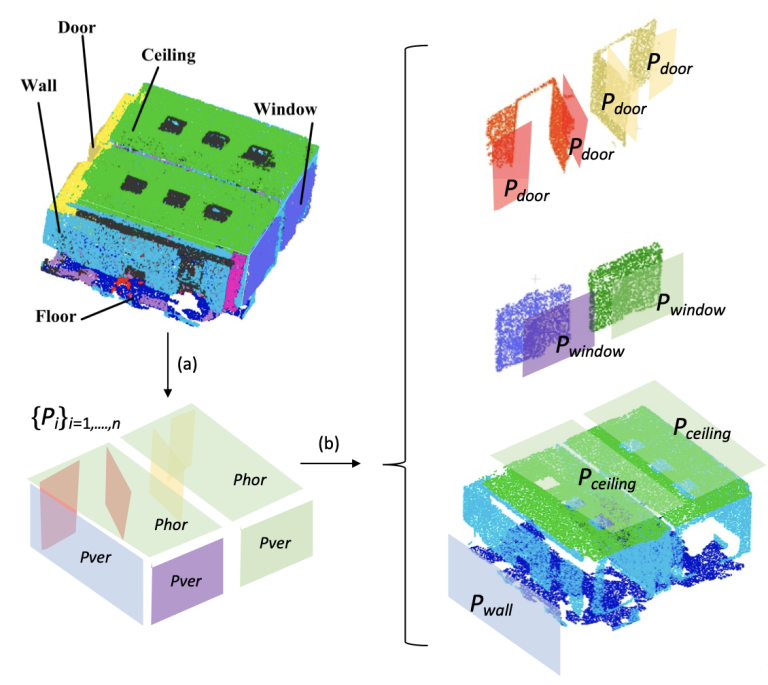
Figure 2: Feature extraction from point cloud data and segmentation: (a) Decompose the data into planar primitives (b) semantic information enrichment to the planar primitives for further refinement.
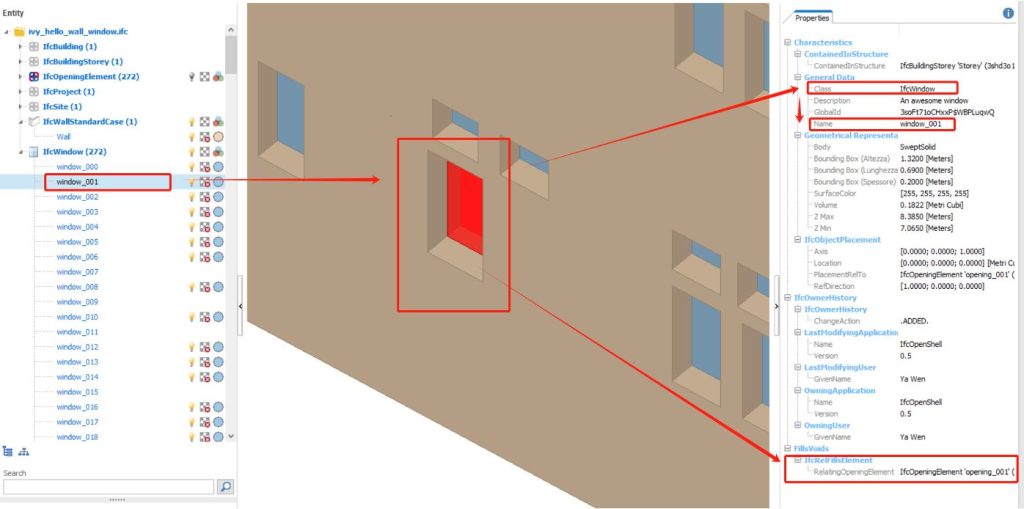
Figure 3: Façade geometric digital twin reconstruction from point cloud data with spatial relationship information.
Conclusion
The journey towards fully automated IFC generation from point cloud data is both promising and challenging. While significant advancements have been made in object recognition, semantic labelling, and BIM integration, the technology still faces limitations, particularly in complex and large-scale projects. Accuracy issues, computational demands, and the need for manual intervention highlight the gap between current capabilities and the ideal of seamless automation. The UK’s research initiatives and large-scale projects like Crossrail have offered valuable insights into both the capabilities and limitations of these technologies. As we continue to advance in BIM and digital construction, the automation of IFC generation will be a key driver in the future of the built environment. However, it currently remains a tool that necessitates both technological advancements and human expertise to achieve the desired outcomes. Ongoing research, particularly in enhanced machine learning models and real-time processing, is paving the way for more efficient and reliable industr evolves, integrating standardised workflows and best practices will be essential for unlocking the full potential of IFC automation, ultimately driving the digital transformation of the construction and architecture sectors.
About the authors
Dr Mahendrini Ariyachandra is an Assistant Professor at University College London (UCL) and Academic Chair of the CSIC Early-Career Academics Panel at University of Cambridge. Her research focuses on advanced construction technologies, particularly automated geometric digital twins for infrastructure. She holds a PhD in Engineering from University of Cambridge and has contributed significantly to the field through research, teaching, and collaborative projects in Building Information Modelling (BIM) and digital twin technologies.
Connect with Mahendrini on LinkedIn | and read her publications on ResearchGate.
Dr Ya Wen is currently a Postdoctoral Research Associate in the Construction Information Technology (CIT) Laboratory, Department of Engineering, at the University of Cambridge. She earned her PhD from the Department of Real Estate and Construction at the University of Hong Kong, where her research focused on semantic knowledge modelling for facilities and asset management using the OWL methodology. At the University of Cambridge, Dr Wen leads the UOC work package for the European Union Agency for the Space Programme-sponsored project, Enabling Innovative Space-Driven Services for Energy Efficient Buildings and Climate Resilient Cities (BUILDSPACE). Her work primarily involves leveraging Machine Learning (ML) and Artificial Intelligence (AI) to automate the creation of geometric digital twin models from building point clouds. These Digital Twins are essential for informed decision-making in energy demand prediction, urban heat management, and urban flood analysis. Additionally, her ongoing research explores innovative methods for Digital Twin construction,incorporating linked data and Large Language Model (LLM) technologies.
Connect with Ya on LinkedIn | and read her publications on ResearchGate.
Leave a comment
You must be logged in to post a comment.
Interesting article, thank you!