IES Launches New Guide: The Practicalities of Creating Performance Digital Twins
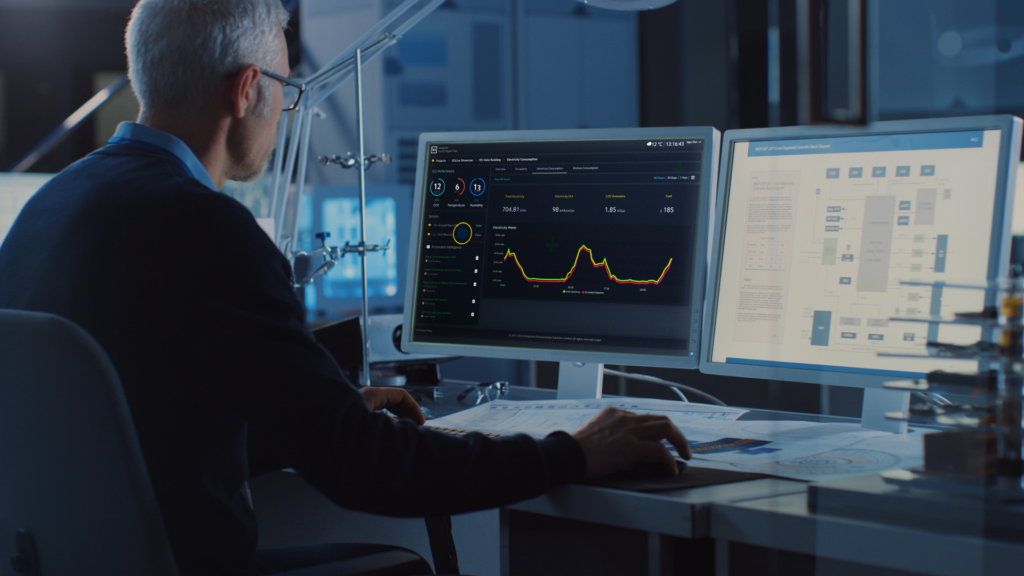
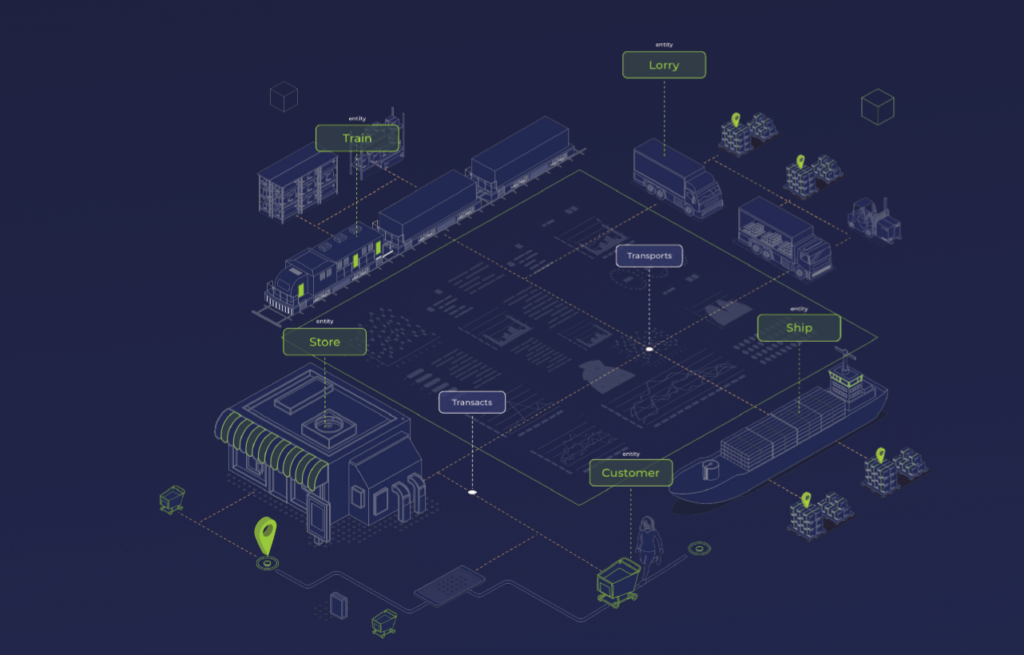
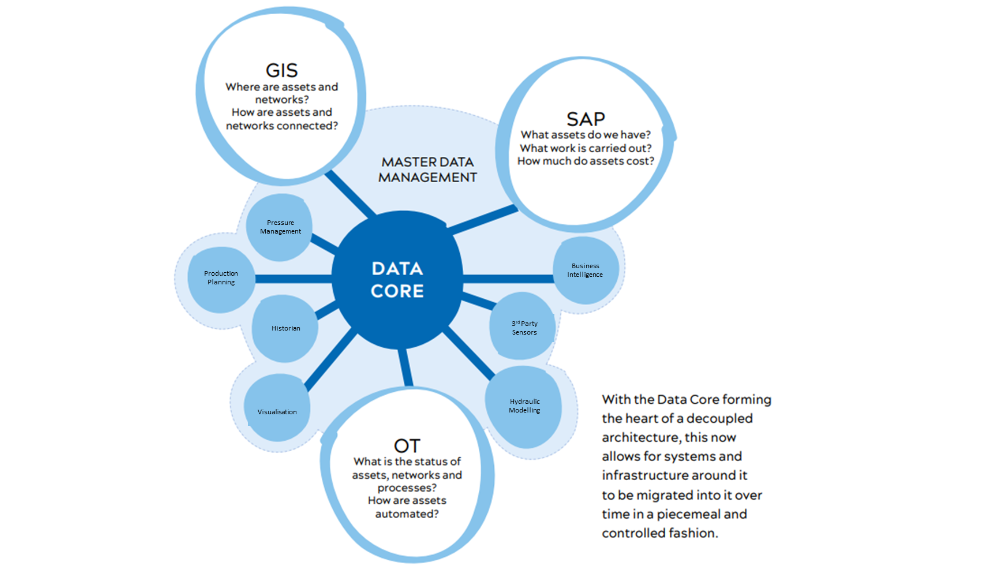
Building performance experts, IES, have launched a new guide exploring the practicalities of creating performance digital twins to improve the performance of existing buildings and support operational…